Mapping tables and attributes
Overview
Mapping is the first step in Master Data Management (MDM) for data unification. Once the data import is completed, map the attributes of imported data with their semantic labels. In the mapping process, you need to do the semantic mapping to get the data into the Lakehouse SQL and prepare it for the Unify (match and merge) process. In skyStudio MDM, you need to map data fields from different business systems or databases in order to consolidate the data into a single, consistent repository. The mapping process consists of the following steps:- Table selection: Identify and select those tables for mapping which have complete information about your customers.
- Attribute selection: Identify and select the most accurate attributes for each table.
- Primary key and semantic type selection: Identify and select a unique primary key for each table and identify the semantic type for each attribute.
- Deduplication (optional): Identify the duplicated records and cleanse your data by eliminating redundancy.
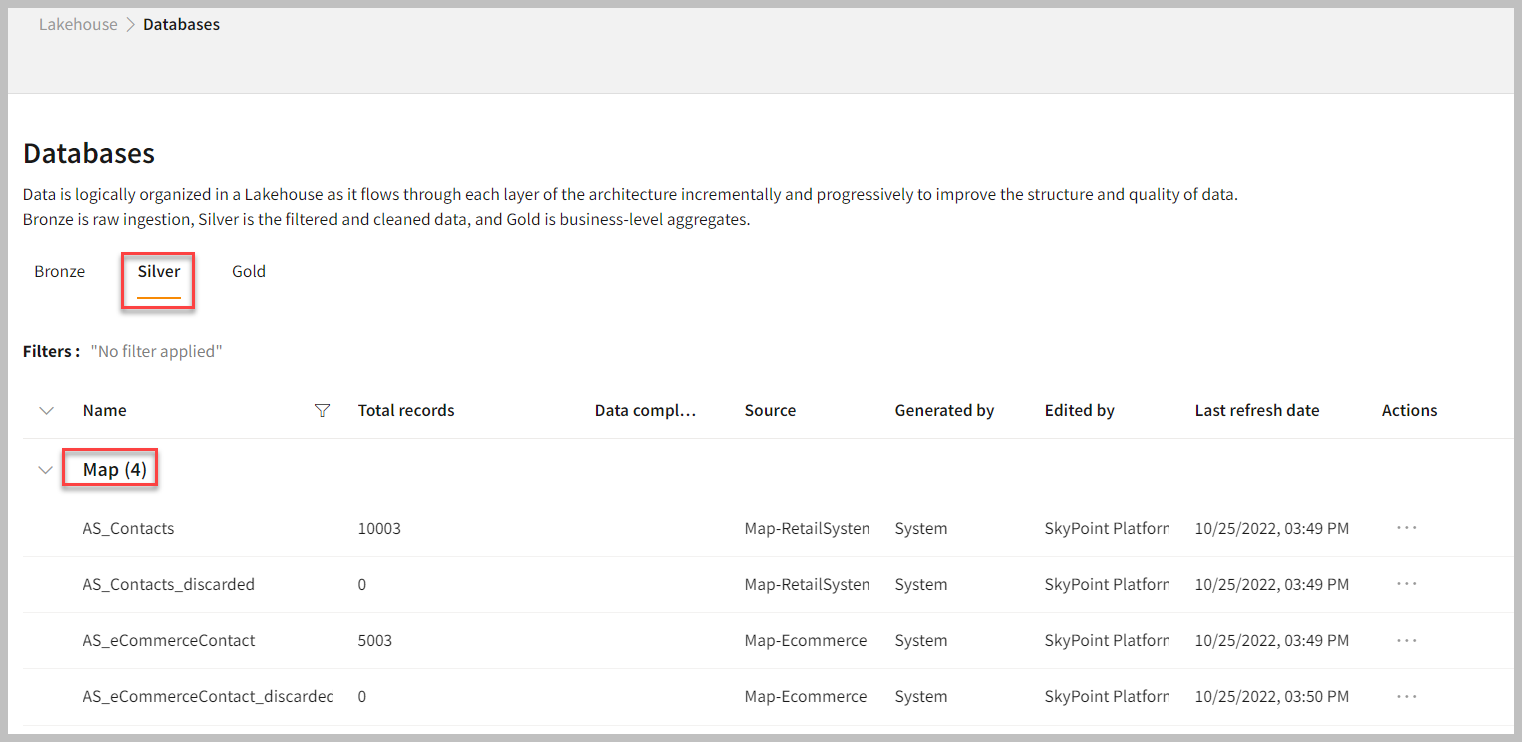
Select tables and attributes
- In the left pane, go to Resolve > Map.
- Click Select tables.
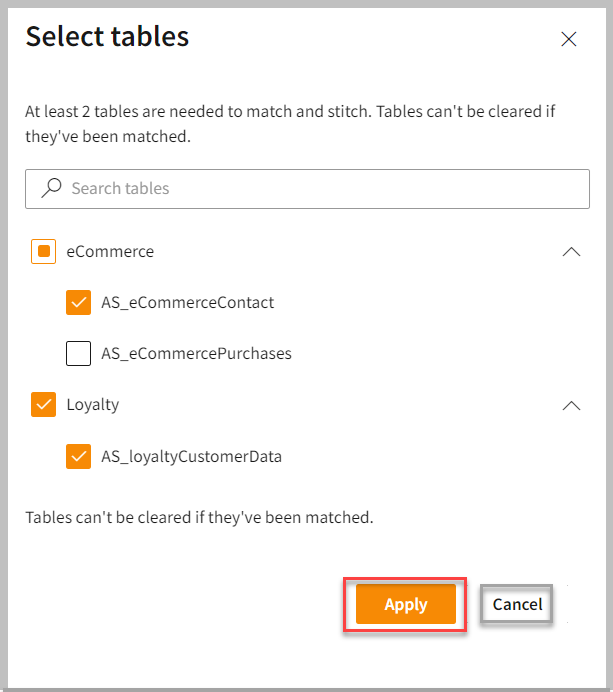
- Expand the list to select the different tables and include all required attributes. You can search for keywords across all tables and attributes that you want to map.
At least two tables are needed to perform the match process. For each selected table, identify the attributes you want to use to match and include them in the unified profile. You can select the required attributes individually from the table or include all attributes by selecting the checkbox.
- Click Apply. The selected tables and attributes are displayed on the Map page.
Select primary key, candidate key, and semantic type for attributes
Follow the below steps to start the Map process: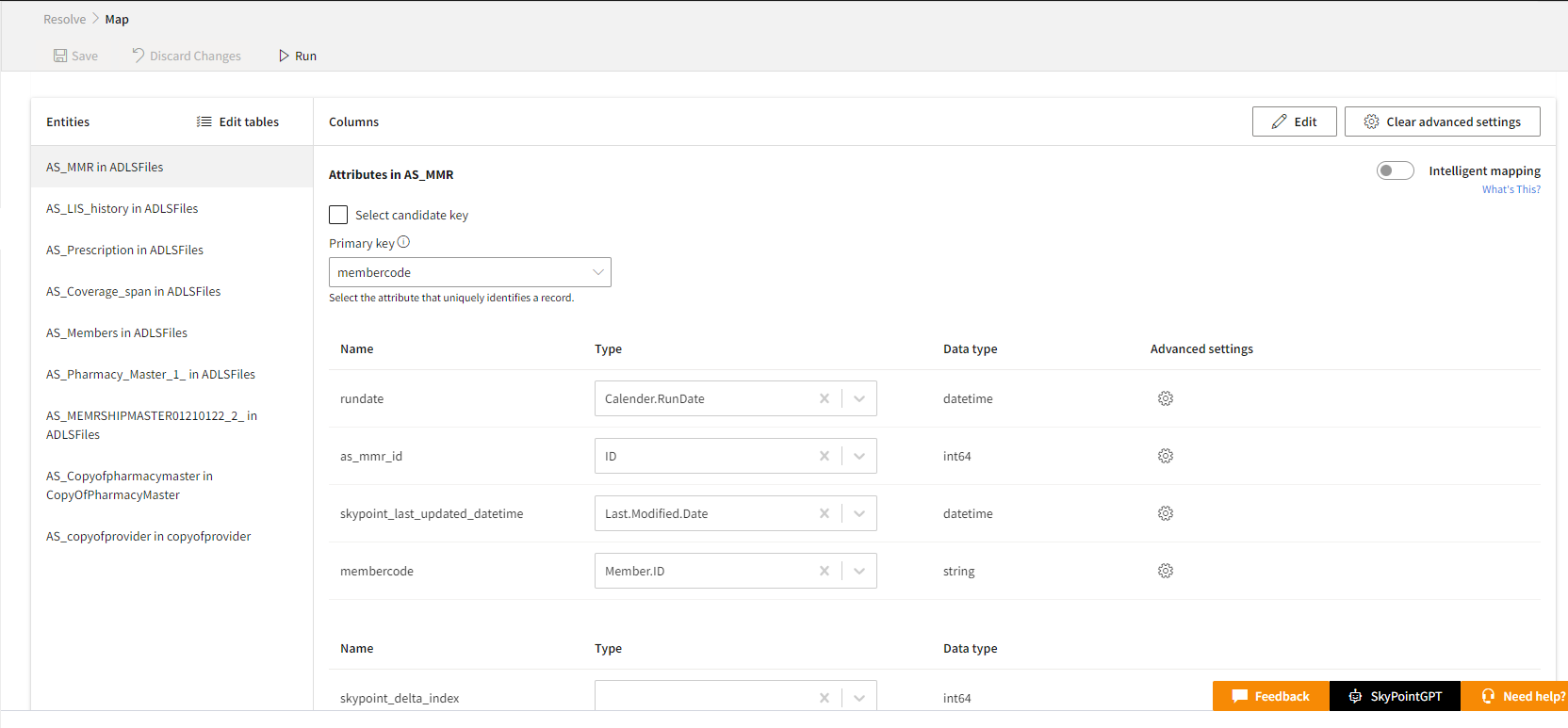
- From the drop-down list, select the Primary key that uniquely identifies a record. It should not include duplicate, missing, or null values.
- If you want to add a candidate key, select the Select candidate key checkbox.
- Select the Candidate key from the drop-down list.
- In the Review mapped field, select the semantic type for attributes.
The system automatically maps the semantic labels based on its inbuilt algorithms. The system displays all mapped attributes in the table above and all unmapped attributes shown in the table below. For attributes that aren’t automatically mapped to a semantic type, are listed under Define the data in the unmapped fields. You can select a semantic mapping for the unmapped attributes to move these to the mapped table or leave them unmapped. Select the attribute that uniquely identifies a record. It should not include duplicate values, missing values, or null values. Data type column display the data type of attribute in the source of data.
- To configure various data cleansing techniques like converting all texts to lower/upper case, removing any spaces between strings, select the Advanced settings. Default normalizations are added for the first name, last name, email address, and phone number fields to reduce data redundancy and eliminate undesirable characteristics.
- Click on each table and complete the mapping for the several types of required fields.
- Click Save.
- Once the application displays Saved successfully, click Run to start the mapping process.
If you run the map for the first time, the system takes it as a full run. For subsequent runs, you can choose between a Full run or an Incremental run. An incremental run adds the data, which was refreshed after the last run. You can get a faster result after the Incremental run.
- To perform the Incremental run, select the date attribute in Last.Modified.Date type.
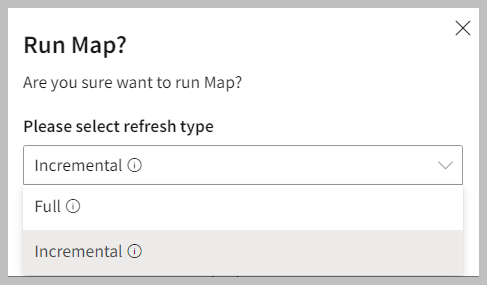
- Choose an appropriate option from the drop-down to run the Map process.
- If necessary, do the following:
| To | Do |
|---|---|
| Discard all the changes from the last save | Click Discard Changes. |
| Cancel the Run that is in progress | Click Cancel Run. |
| Add or remove the attributes | Click Edit. |
| Discard advanced settings | Click Clear advanced settings. |
| See the last 3 map versions and compare with each other | Click Versions |
| See the run history of the mapping process | Click Run history. |
Duplicating the record details
The Deduplication process identifies the duplicated records and cleanses your data by eliminating redundant data. For example, there are 100 individual data records, but 50 out of the 100 records are duplicates. To unify the data, you must remove the duplicates so that only 50 unique records will pass to the next step in the process. You can set up rules to eliminate duplicate records within the table. Defining your own deduplication rules gives you the flexibility to select the best record to keep.To identify and resolve the duplicated records
- Go to Resolve > Map.
- In the Duplicated records details section, select Set tables. If deduplication rules are already set then you can click Edit to modify the tables.
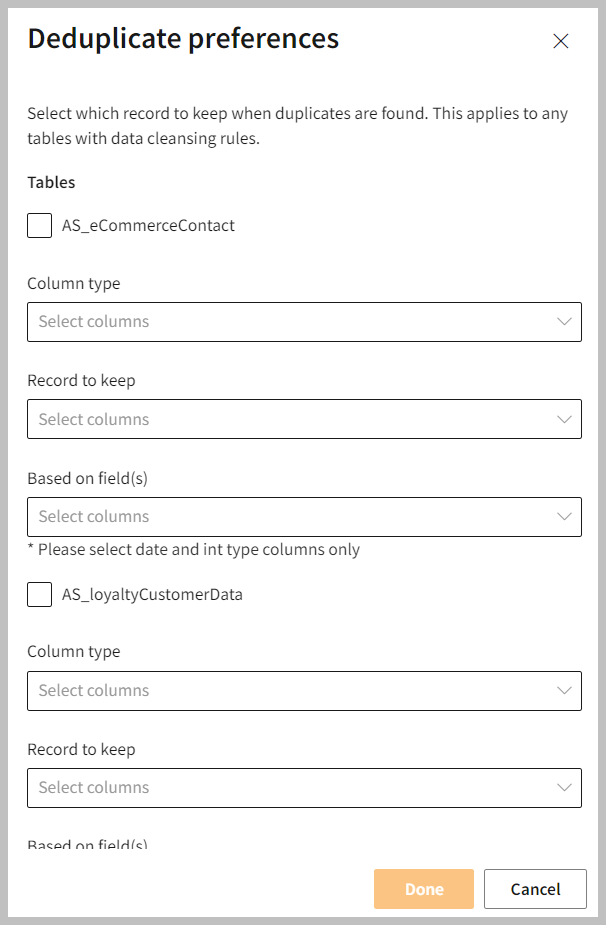
- In the Deduplicate preferences pane, select the Tables.
Deduplicate preference | Description |
|---|---|
| Column Type | Option to select the column type to figure out the duplicated data. |
| Record to keep | Allows you to identify and select the most populated attribute fields, most recent, and least recent records. You can choose one of three options to determine which record to keep if a duplicate is found. |
| Most recent | Identifies the record based on the most recency. |
| Least recent | Identifies the record based on the least recency. |
| Most filled | Identifies the record with the most populated attribute fields. |
| Based on field(s) | Allows you to select the most populated attribute fields. |
- Choose the criteria for deduplicate preference from Column Type > Record to Keep > Based on field (s).
- Select Done.
- Click Save > Run.
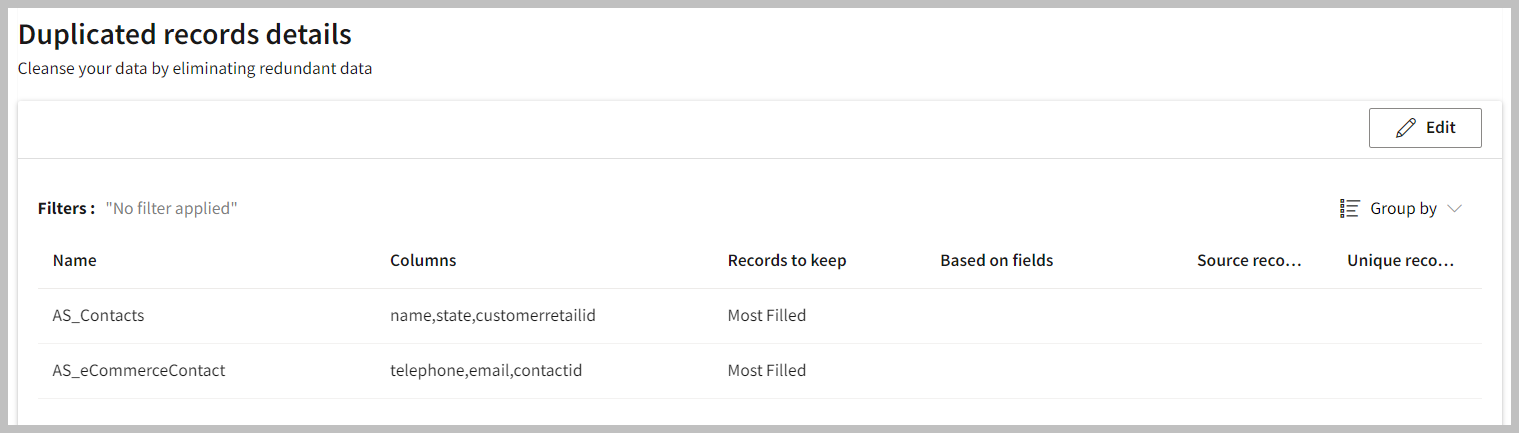
- If you want to modify the Deduplicate preferences, click the Edit button and select Done to apply your changes.